In time series analysis, the Box–Jenkins methodology, named after the statisticians George Box and Gwilym Jenkins, applies autoregressive moving average ARMA or ARIMA models to find the best fit of a time series to past values of this time series, in order to make forecasts.
Modeling approach
The original model uses an iterative three-stage modeling approach:
For higher-order autoregressive processes, the sample autocorrelation needs to be supplemented with a partial autocorrelation plot. The partial autocorrelation of an AR(p) process becomes zero at lag p + 1 and greater, so we examine the sample partial autocorrelation function to see if there is evidence of a departure from zero. This is usually determined by placing a 95% confidence interval on the sample partial autocorrelation plot (most software programs that generate sample autocorrelation plots will also plot this confidence interval). If the software program does not generate the confidence band, it is approximately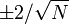 , with N denoting the sample size.
, with N denoting the sample size.
The sample partial autocorrelation function is generally not helpful for identifying the order of the moving average process.
Mixed models difficult to identify
In practice, the sample autocorrelation and partial autocorrelation functions are random variables and will not give the same picture as the theoretical functions. This makes the model identification more difficult. In particular, mixed models can be particularly difficult to identify.
Although experience is helpful, developing good models using these sample plots can involve much trial and error. For this reason, in recent years information-based criteria such as FPE (final prediction error) and AIC (Akaike Information Criterion) and others have been preferred and used. These techniques can help automate the model identification process. These techniques require computer software to use. Fortunately, these techniques are available in many commercial statistical software programs that provide ARIMA modeling capabilities.
For additional information on these techniques, see Brockwell and Davis (1987, 2002).
The main approaches to fitting Box–Jenkins models are non-linear least squares and maximum likelihood estimation. Maximum likelihood estimation is generally the preferred technique. The likelihood equations for the full Box–Jenkins model are complicated and are not included here. See (Brockwell and Davis, 1987,2002) for the mathematical details.
That is, the error term At is assumed to follow the assumptions for a stationary univariate process. The residuals should be white noise (or independent when their distributions are normal) drawings from a fixed distribution with a constant mean and variance. If the Box–Jenkins model is a good model for the data, the residuals should satisfy these assumptions.
If these assumptions are not satisfied, one needs to fit a more appropriate model. That is, go back to the model identification step and try to develop a better model. Hopefully the analysis of the residuals can provide some clues as to a more appropriate model.
One way to assess if the residuals from the Box–Jenkins model follow the assumptions is to generate statistical graphics (including an autocorrelation plot) of the residuals. One could also look at the value of the Box–Ljung statistic.
Modeling approach
The original model uses an iterative three-stage modeling approach:
- Model identification and model selection: making sure that the variables are stationary, identifying seasonality in the dependent series (seasonally differencing it if necessary), and using plots of the autocorrelation and partial autocorrelation functions of the dependent time series to decide which (if any) autoregressive or moving average component should be used in the model.
- Parameter estimation using computation algorithms to arrive at coefficients which best fit the selected ARIMA model. The most common methods use maximum likelihood estimation or non-linear least-squares estimation.
- Model checking by testing whether the estimated model conforms to the specifications of a stationary univariate process. In particular, the residuals should be independent of each other and constant in mean and variance over time. (Plotting the mean and variance of residuals over time and performing a Ljung-Box test or plotting autocorrelation and partial autocorrelation of the residuals are helpful to identify misspecification.) If the estimation is inadequate, we have to return to step one and attempt to build a better model.
[edit] Box-Jenkins model identification
[edit] Stationarity and seasonality
The first step in developing a Box–Jenkins model is to determine if the time series is stationary and if there is any significant seasonality that needs to be modeled.[edit] Detecting stationarity
Stationarity can be assessed from a run sequence plot. The run sequence plot should show constant location and scale. It can also be detected from an autocorrelation plot. Specifically, non-stationarity is often indicated by an autocorrelation plot with very slow decay.[edit] Detecting seasonality
Seasonality (or periodicity) can usually be assessed from an autocorrelation plot, a seasonal subseries plot, or a spectral plot.[edit] Differencing to achieve stationarity
Box and Jenkins recommend the differencing approach to achieve stationarity. However, fitting a curve and subtracting the fitted values from the original data can also be used in the context of Box–Jenkins models.[edit] Seasonal differencing
At the model identification stage, the goal is to detect seasonality, if it exists, and to identify the order for the seasonal autoregressive and seasonal moving average terms. For many series, the period is known and a single seasonality term is sufficient. For example, for monthly data one would typically include either a seasonal AR 12 term or a seasonal MA 12 term. For Box–Jenkins models, one does not explicitly remove seasonality before fitting the model. Instead, one includes the order of the seasonal terms in the model specification to the ARIMA estimation software. However, it may be helpful to apply a seasonal difference to the data and regenerate the autocorrelation and partial autocorrelation plots. This may help in the model identification of the non-seasonal component of the model. In some cases, the seasonal differencing may remove most or all of the seasonality effect.[edit] Identify p and q
Once stationarity and seasonality have been addressed, the next step is to identify the order (i.e., the p and q) of the autoregressive and moving average terms.[edit] Autocorrelation and partial autocorrelation plots
The primary tools for doing this are the autocorrelation plot and the partial autocorrelation plot. The sample autocorrelation plot and the sample partial autocorrelation plot are compared to the theoretical behavior of these plots when the order is known.[edit] Order of autoregressive process (p)
Specifically, for an AR(1) process, the sample autocorrelation function should have an exponentially decreasing appearance. However, higher-order AR processes are often a mixture of exponentially decreasing and damped sinusoidal components.For higher-order autoregressive processes, the sample autocorrelation needs to be supplemented with a partial autocorrelation plot. The partial autocorrelation of an AR(p) process becomes zero at lag p + 1 and greater, so we examine the sample partial autocorrelation function to see if there is evidence of a departure from zero. This is usually determined by placing a 95% confidence interval on the sample partial autocorrelation plot (most software programs that generate sample autocorrelation plots will also plot this confidence interval). If the software program does not generate the confidence band, it is approximately
, with N denoting the sample size.[edit] Order of moving-average process (q)
The autocorrelation function of a MA(q) process becomes zero at lag q + 1 and greater, so we examine the sample autocorrelation function to see where it essentially becomes zero. We do this by placing the 95% confidence interval for the sample autocorrelation function on the sample autocorrelation plot. Most software that can generate the autocorrelation plot can also generate this confidence interval.The sample partial autocorrelation function is generally not helpful for identifying the order of the moving average process.
[edit] Shape of autocorrelation function
The following table summarizes how one can use the sample autocorrelation function for model identification.Mixed models difficult to identify
In practice, the sample autocorrelation and partial autocorrelation functions are random variables and will not give the same picture as the theoretical functions. This makes the model identification more difficult. In particular, mixed models can be particularly difficult to identify.
Although experience is helpful, developing good models using these sample plots can involve much trial and error. For this reason, in recent years information-based criteria such as FPE (final prediction error) and AIC (Akaike Information Criterion) and others have been preferred and used. These techniques can help automate the model identification process. These techniques require computer software to use. Fortunately, these techniques are available in many commercial statistical software programs that provide ARIMA modeling capabilities.
For additional information on these techniques, see Brockwell and Davis (1987, 2002).
[edit] Box–Jenkins model estimation
Estimating the parameters for the Box–Jenkins models is a quite complicated non-linear estimation problem. For this reason, the parameter estimation should be left to a high quality software program that fits Box–Jenkins models. Fortunately, many statistical software programs now fit Box–Jenkins models.The main approaches to fitting Box–Jenkins models are non-linear least squares and maximum likelihood estimation. Maximum likelihood estimation is generally the preferred technique. The likelihood equations for the full Box–Jenkins model are complicated and are not included here. See (Brockwell and Davis, 1987,2002) for the mathematical details.
[edit] Box–Jenkins model diagnostics
[edit] Assumptions for a stable univariate process
Model diagnostics for Box–Jenkins models is similar to model validation for non-linear least squares fitting.That is, the error term At is assumed to follow the assumptions for a stationary univariate process. The residuals should be white noise (or independent when their distributions are normal) drawings from a fixed distribution with a constant mean and variance. If the Box–Jenkins model is a good model for the data, the residuals should satisfy these assumptions.
If these assumptions are not satisfied, one needs to fit a more appropriate model. That is, go back to the model identification step and try to develop a better model. Hopefully the analysis of the residuals can provide some clues as to a more appropriate model.
One way to assess if the residuals from the Box–Jenkins model follow the assumptions is to generate statistical graphics (including an autocorrelation plot) of the residuals. One could also look at the value of the Box–Ljung statistic.